How about using 1Password with Ansible?
2021-11-23 - Progress - Tony Finch
i have been looking at how to use the 1Password op command-line tool
with Ansible. It works fairly nicely.
You need to install the 1Password command-line tool.
You need a recent enough Ansible with the community.general
collection installed, so that it includes the onepassword lookup
plugin
To try out an example, create an op.yml file containing:
---
- hosts: localhost
tasks:
- name: test 1password
debug:
msg: <{{ lookup("onepassword",
"Mythic Beasts",
field="username") }}>
You might need to choose an item other than Mythic Beasts if you don't have a login with them.
Initialize op and start a login session by typing:
eval $(op signin)
Then see if Ansible works:
ansible-playbook op.yml
Amongst the Ansible verbiage, I get the output:
ok: [localhost] => {
"msg": "<hostmaster@cam.ac.uk>"
}
Some more detailed notes follow...
aims
I want it to be easy to keep secrets encrypted when they are not in use. Things like ssh private keys, static API credentials, etc. "Not in use" means when not installed on the system that needs them.
In particular, secrets should normally be encrypted on any systems on which we run Ansible, and decrypted only when they need to be deployed.
And it should be easy enough that everyone on the team is able to use it.
what about regpg?
I wrote regpg to tackle this problem in a way I consider to be safe. It is modestly successful: people other than me use it, in more places than just Cambridge University Information Services.
But it was not the right tool for the Network Systems team in which I
work. It isn't possible for a simple wrapper like regpg to fix
gpg's usability issues: in particular, it's horrible if you don't
have a unix desktop, and it's horrible over ssh.
1password
Since I wrote regpg we have got 1Password set up for the team. I
have used 1Password for my personal webby login things for years, and
I'm happy to use it at work too.
There are a couple of ways to use 1Password for ops automation...
secrets automation and 1password connect
First I looked at the relatively new support for "secrets automation" with 1Password. It is based around a 1Password Connect server, which we would install on site. This can provide an application with short-term access to credentials on demand via a REST API. (Sounds similar to other cloudy credential servers such as Hashicorp Vault or AWS IAM.)
However, the 1Password Connect server needs credentials to get access to our vaults, and our applications that use 1Password Connect need API access tokens. And we need some way to deploy these secrets safely. So we're back to square 1.
1password command line tool
The op command has
basically the same functionality as 1Password's GUIs. It has a similar
login model, in that you type in your passphrase to unlock the vault,
and it automatically re-locks after an inactivity timeout. (This is
also similar to the way regpg relies on the gpg agent to cache
credentials so that an Ansible run can deploy lots of secrets with
only one password prompt.)
So op is clearly the way to go, though there are a few niggles:
The
opconfiguration file contains details of the vaults it has been told about, including your 1Password account secret key in cleartext. So the configuration file is sensitive and should be kept safe. (It would be better ifopstored the account secret key encrypted using the user's password.)op signinuses an environment variable to store the session key, which is not ideal because it is easy to accidentally leak the contents of environment variables. It isn't obvious that a collection of complicated Ansible playbooks can be trusted to handle environment variables carefully.It sometimes reauires passing secrets on the command line, which exposes them to all users on the system. For instance, the documented way to find out whether a session has timed out is with a command line like:
$ op signin --session $OP_SESSION_example example
I have reported these issues to the 1Password developers.
Ansible and op
Ansible's community.general collection includes
some handy wrappers around the op command, in particular the
onepassword lookup plugin. (I am not so keen on the others
because the documentation suggests to me that they do potentially
unsafe things with Ansible variables.)
One of the problems I had with regpg was bad behaviour that occurred
when an Ansible playbook was started when the gpg agent wasn't ready;
the fix was to add a task to the start of the Ansible playbook which
polls the gpg agent in a more controlled manner.
I think a similar preflight task might be helpful for op:
check if there is an existing
opsession; if not, prompt for a passphrase to start a sessionset up a wrapper command for
opthat gets the session key from a more sensible place than the environment
To refresh a session safely, and work around the safety issue with op
signin mentioned above, we can test the session using a benign
command such as op list vaults or op get account, and run op
signin if that fails.
The wrapper script can be as simple as:
#!/bin/sh OP_SESSION_example=SQUEAMISHOSSIFRAGE /usr/local/bin/op "$@"
Assuming there is somewhere sensible and writable on $PATH...
Review of 2019
2020-01-29 - Progress - Tony Finch
Some notes looking back on what happened last year...
DNSSEC algorithm rollover HOWTO
2020-01-15 - Progress - Tony Finch
Here are some notes on how to upgrade a zone's DNSSEC algorithm using BIND. These are mainly written for colleagues in the Faculty of Maths and the Computer Lab, but they may be of interest to others.
I'll use botolph.cam.ac.uk as the example zone. I'll assume the
rollover is from algorithm 5 (RSASHA1) to algorithm 13
(ECDSA-P256-SHA-256).
A WebDriver tutorial
2019-12-12 - Progress - Tony Finch
As part of my work on superglue I have resumed work on the WebDriver scripts I started in January. And, predictably because they were a barely working mess, it took me a while to remember how to get them working again.
So I thought it might be worth writing a little tutorial describing how I am using WebDriver. These notes have nothing to do with my scripts or the DNS; it's just about the logistics of scripting a web site.
Make before break
2019-11-18 - Progress - Tony Finch
This afternoon I did a tricky series of reconfigurations. The immediate need was to do some prep work for improving our DNS blocks; I also wanted to make some progress towards completing the renaming/renumbering project that has been on the back burner for most of this year; and I wanted to fix a bad quick-and-dirty hack I made in the past.
Along the way I think I became convinced there's an opportunity for a significant improvement.
YAML and Markdown
2019-11-13 - Progress - Tony Finch
This web site is built with a static site generator. Each page on the site has a source file written in Markdown. Various bits of metadata (sidebar links, title variations, blog tags) are set in a bit of YAML front-matter in each file.
Both YAML and Markdown are terrible in several ways.
YAML is ridiculously over-complicated and its minimal syntax can hide minor syntax errors turning them into semantic errors. (A classic example is a list of two-letter country codes, in which Norway (NO) is transmogrified into False.)
Markdown is poorly defined, and has a number of awkward edge cases where its vagueness causes gotchas. It has spawned several dialects to fill in some of its inadequacies, which causes compatibility problems.
However, they are both extremely popular and relatively pleasant to write and read.
For this web site, I have found that a couple of simple sanity checks are really helpful for avoiding cockups.
YAML documents
One of YAML's peculiarities is its idea of storing multiple documents in a stream.
A YAML document consists of a --- followed by a YAML value. You can
have multiple documents in a file, like these two:
--- document: one --- document: two
YAML values don't have to be key/value maps: they can also be simple strings. So you can also have a two-document file like:
--- one --- two
YAML has a complicated variety of multiline string
syntaxes. For the simple case of a
preformatted string, you can use the | sigil. This document is like
the previous one, except that the strings have newlines:
--- | one --- | two
YAML frontmatter
The source files for this web site each start with something like this (using this page as an example, and cutting off after the title):
--- tags: [ progress ] authors: [ fanf2 ] --- | YAML and Markdown =================
This is a YAML stream consisting of two documents, the front matter (a key/value map) and the Markdown page body (a preformatted string).
There's a fun gotcha. I like to use underline for headings because it helps to make them stand out in my editor. If I ever have a three-letter heading, that splits the source file into a third YAML document. Oops!
So my static site generator's first sanity check is to verify there are exactly two YAML documents in the file.
Aside: There is also a YAML document end marker, ..., but I have
not had problems with accidentally truncated pages because of it!
Tabs and indentation
Practically everything (terminals, editors, pagers, browsers...) by default has tab stops every 8 columns. It's a colossal pain in the arse to have to reconfigure everything for different tab stops, and even more of a pain in the arse if you have to work on projects that expect different tab stop settings. (PostgreSQL is the main offender of the projects I have worked with, bah.)
I don't mind different coding styles, or different amounts of indentation, so long as the code I am working on has a consistent style. I tend to default to KNF (the Linux / BSD kernel normal form) if I'm working on my own stuff, which uses one tab = one indent.
The only firm opinion I have is that if you are not using 8 column tab stops and tabs for indents, then you should use spaces for indents.
Indents in Markdown
Markdown uses indentation for structure, either a 4-space indent or a tab indent. This is a terrible footgun if tabs are displayed in the default way and you accidentally have a mixture of spaces and tabs: an 8 column indent might be one indent level or two, depending on whether it is a tab or spaces, and the difference is mostly invisible.
So my static site generator's second sanity check is to ensure there are no tabs in the Markdown.
This is a backup check, in case my editor configuration is wrong and unintentionally leaks tabs.
Metadata for login credentials
2019-09-28 - Progress - Tony Finch
This month I have been ambushed by domain registration faff of multiple kinds, so I have picked up a few tasks that have been sitting on the back burner for several months. This includes finishing the server renaming that I started last year, solidifying support for updating DS records to support automated DNSSEC key rollovers, and generally making sure our domain registration contact information is correct and consistent.
I have a collection of domain registration management scripts called superglue, which have always been an appalling barely-working mess that I fettle enough to get some task done then put aside in a slightly different barely-working mess.
I have reduced the mess a lot by coming up with a very simple convention for storing login credentials. It is much more consistent and safe than what I had before.
The login problem
One of the things superglue always lacked is a coherent way to
handle login credentials for registr* APIs. It predates regpg by a
few years, but regpg only deals with how to store the secret parts
of the credentials. The part that was awkward was how to store the
non-secret parts: the username, the login URL, commentary about what
the credentials are for, and so on. The IP Register system also has
this problem, for things like secondary DNS configuration APIs and
database access credentials.
There were actually two aspects to this problem.
Ad-hoc data formats
My typical thoughtless design process for the superglue code that
loaded credentials was like, we need a username and a password, so
we'll bung them in a file separated by a colon. Oh, this service needs
more than that, so we'll have a multi-line file with fieldname colon
value on each line. Just terrible.
I decided that the best way to correct the sins of the past would be to use an off-the-shelf format, so I can delete half a dozen ad-hoc parsers from my codebase. I chose YAML not because it is good (it's not) but because it is well-known, and I'm already using it for Ansible playbooks and page metadata for this web server's static site generator.
Secret hygiene
When designing regpg I formulated some guidelines for looking after secrets safely.
From our high-level perspective, secrets are basically blobs of random data: we can't usefully look at them or edit them by hand. So there is very little reason to expose them, provided we have tools (such as regpg) that make it easy to avoid doing so.
Although regpg isn't very dogmatic, it works best when we put each secret in its own file. This allows us to use the filename as the name of the secret, which is available without decrypting anything, and often all the metadata we need.
That weasel word "often" tries to hide the issue that when I wrote it two years ago I did not have an answer to the question, what if the filename is not all the metadata we need?
I have found that my ad-hoc credential storage formats are very bad
for secret hygiene. They encourage me to use the sinful regpg edit
command, and decrypt secrets just to look at the non-secret parts, and
generally expose secrets more than I should.
If the metadata is kept in a separate cleartext YAML file, then the comments in the YAML can explain what is going on. If we strictly follow the rule that there's exactly one secret in an encrypted file and nothing else, then there's no reason to decrypt secrets unnecessarily everything we need to know is in the cleartext YAML file.
Implementation
I have released regpg-1.10 which includes ReGPG::Login a Perl library for loading credentials stored in my new layout convention. It's about 20 simple lines of code.
Each YAML file example-login.yml typically looks like:
# commentary explaining the purpose of this login --- url: https://example.com/login username: alice gpg_d: password: example-login.asc
The secret is in the file example-login.asc alongside. The library
loads the YAML and inserts into the top-level object the decrypted
contents of the secrets listed in the gpg_d sub-object.
For cases where the credentials need to be available without someone
present to decrypt them, the library looks for a decrypted secret file
example-login (without the .asc extension) and loads that instead.
The code loading the file can also list the fields that it needs, to provide some protection against cockups. The result looks something like,
my $login = read_login $login_file, qw(username password url);
my $auth = $login->{username}.':'.$login->{password};
my $authorization = 'Basic ' . encode_base64 $auth, '';
my $r = LWP::UserAgent->new->post($login->{url},
Authorization => $authorization,
Content_Type => 'form-data',
Content => [ hello => 'world' ]
);
Deployment
Secret storage in the IP Register system is now a lot more coherent, consistent, better documented, safer, ... so much nicer than it was. And I got to delete some bad code.
I only wish I had thought of this sooner!
Migrating a website with Let's Encrypt
2019-09-03 - Progress - Tony Finch
A few months ago I wrote about Let's Encrypt on clustered Apache web servers. This note describes how to use a similar trick for migrating a web site to a new server.
The situation
You have an existing web site, say www.botolph.cam.ac.uk, which is
set up with good TLS security.
It has permanent redirects from http://… to https://… and from
bare botolph.cam.ac.uk to www.botolph.cam.ac.uk. Permanent
redirects are cached very aggressively by browsers, which take
"permanent" literally!
The web site has strict-transport-security with a long lifetime.
You want to migrate it to a new server.
The problem
If you want to avoid an outage, the new server must have similarly good TLS security, with a working certificate, before the DNS is changed from the old server to the new server.
But you can't easily get a Let's Encrypt certificate for a server until after the DNS is pointing at it.
A solution
As in my previous note, we can use the fact that Let's Encrypt will follow redirects, so we can provision a certificate on the new server before changing the DNS.
on the old server
In the http virtual hosts for all the sites that are being migrated
(both botolph.cam.ac.uk and www.botolph.cam.ac.uk in our example),
we need to add redirects like
Redirect /.well-known/acme-challenge/ \
http://{{newserver}}/.well-known/acme-challenge/
where {{newserver}} is the new server's host name (or IP address).
This redirect needs to match more specifically than the existing
http -> https redirect, so that Let's Encrypt is sent to the new
server, while other requests are bounced to TLS.
on the new server
Run the ACME client to get a certificate for the web sites that are
migrating. The new server needs to serve ACME challenges for the web
site names botolph.cam.ac.uk and www.botolph.cam.ac.uk from the
{{newserver}} default virtual host. This is straightforward with
the ACME client I use, dehydrated.
migrate
It should now be safe to update the DNS to move the web sites from the old server to the new one. To make sure, there are various tricks you can use to test the new server before updating the DNS [1] [2].
More complicated ops
2019-07-18 - Progress - Tony Finch
This week I am back porting ops pages from v2 to v3.
I'm super keen to hear any complaints you have about the existing user interface. Please let ip-register@uis.cam.ac.uk know of anything you find confusing or awkward! Not everything will be addressed in this round of changes but we'll keep them in mind for future work.
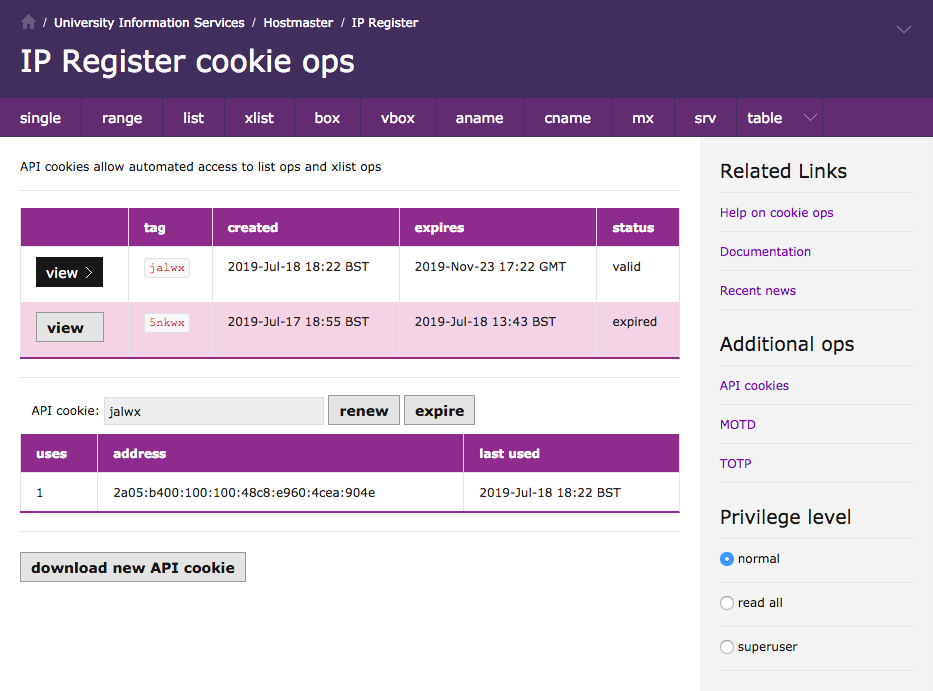
API cookies
Jackdaw has separate pages to download an API cookie and manage API cookies. The latter is modal and switches between an overview list and a per-cookie page.
In v3 they have been commbined into a single page (screenshot below) with less modality, and I have moved the verbiage to a separate API cookie documentation page.
While I was making this work I got terribly confused that my v3 cookie page did not see the same list of cookies as Jackdaw's manage-cookies page, until I realised that I should have been looking at the dev database on Ruff. The silliest bugs take the longest to fix...
Single ops
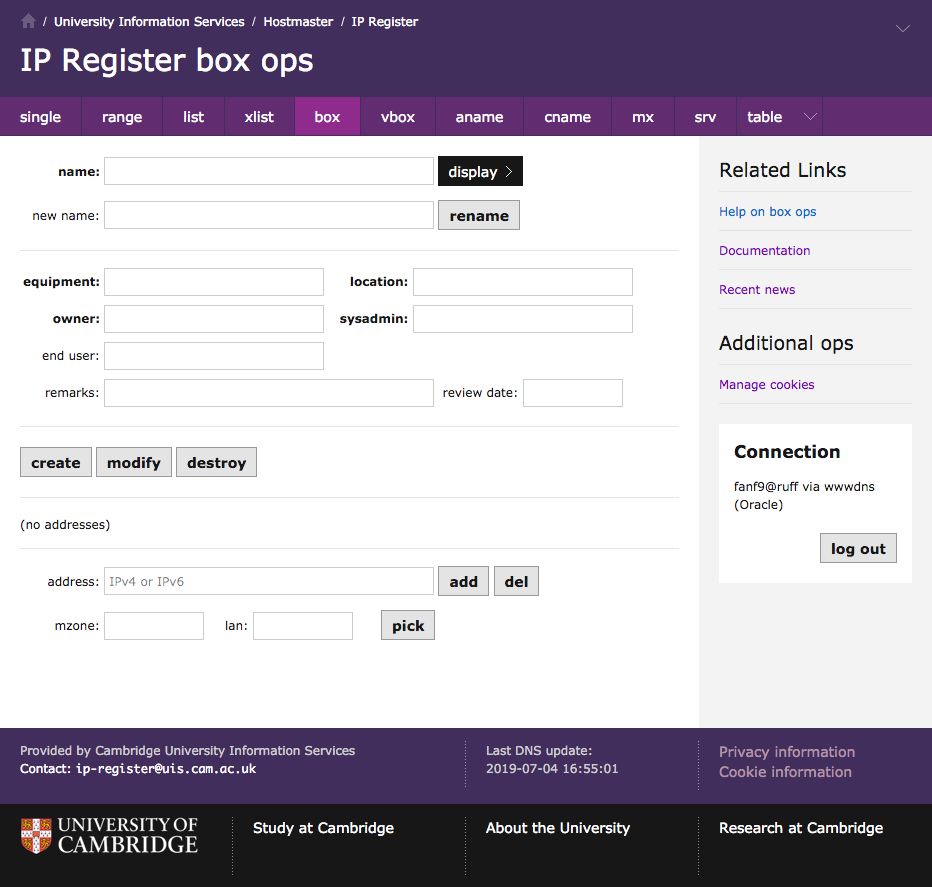
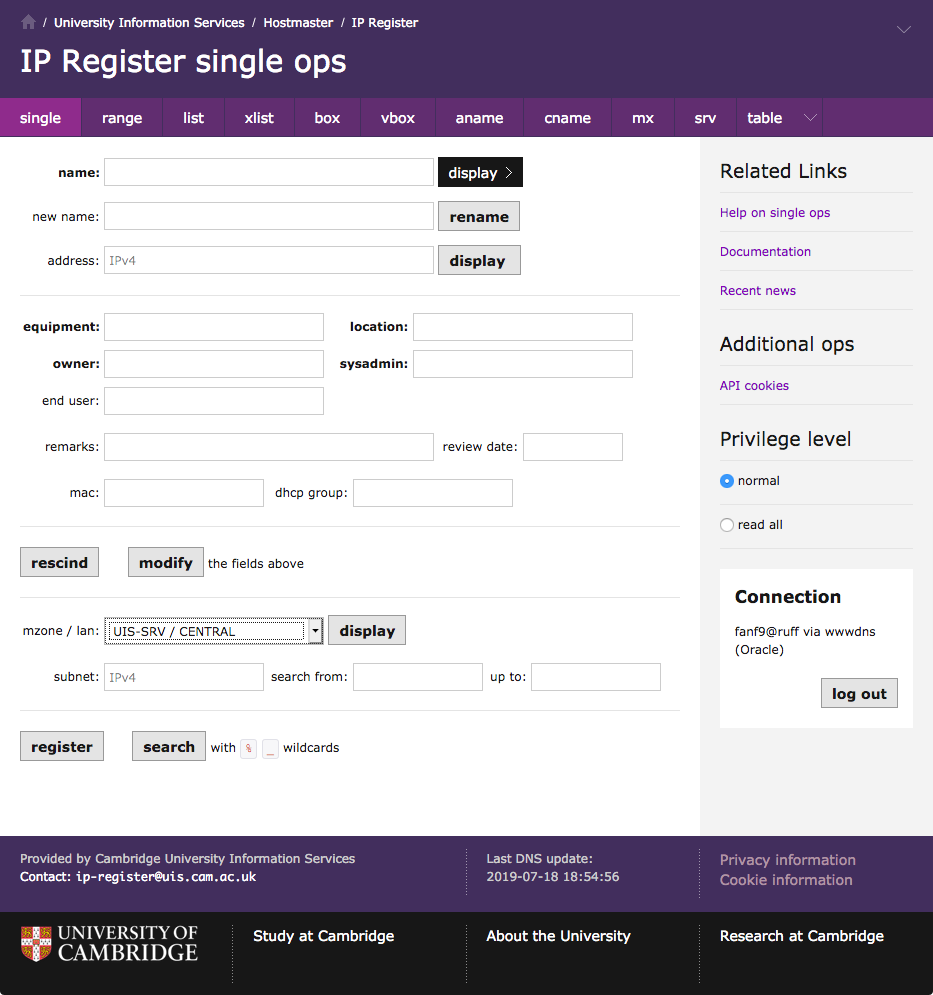
Today I have started mocking up a v3 "single ops" page. This is a bit of a challenge, because the existing page is rather cluttered and confusing, and it's hard to improve within the constraint that I'm not changing its functionality.
I have re-ordered the page to be a closer match to the v3 box ops
page. The main difference is that the
address field is near the top because it is frequently used as a
primary search key.
{kind=link}
There is a downside to this placement, because it separates the address from the other address-related fields which are now at the bottom: the address's mzone, lan, subnet, and the mac and dhcp group that are properties of the address rather than properties of the box.
On the other hand, I wanted to put the address-related fields near the
register and search buttons to hint that they are kind of related:
you can use the address-related fields to get the database to
automatically pick an address for registration following those
constraints, or you can search for boxes within the constraints.
Did you know that (like table ops but unlike most other pages) you can use SQL-style wildcards to search on the single ops page?
Finally, a number of people said that the mzone / lan boxes are super awkward, and they explicitly asked for a drop-down list. This breaks the rule against no new functionality, but I think it will be simple enough that I can get away with it. (Privileged users still get the boxes rather than a drop-down with thousands of entries!)
Refactored error handling
2019-07-12 - Progress - Tony Finch
This week I have been refactoring the error handling of the "v3" IP Register web interface that I posted screenshots of last week. There have not been any significant visible changes, but I have reduced the code size by nearly 200 lines compared to last week, and fixed a number of bugs in the process.
On top of the previous refactorings, the new code is quite a lot smaller than the existing web interface on Jackdaw.
| page | v2 lines | v3 lines | change |
|---|---|---|---|
| box | 283 | 151 | 53% |
| vbox | 327 | 182 | 55% |
| aname | 244 | 115 | 47% |
| cname | 173 | 56 | 32% |
| mx | 253 | 115 | 45% |
| srv | 272 | 116 | 42% |
| motd | 51 | 22 | 43% |
| totp | 66 | 20 | 30% |
Eight ops pages ported
2019-07-04 - Progress - Tony Finch
This week I passed a halfway mark in porting web pages from the old IP Register web interface on Jackdaw to the "v3" web interface. The previous note on this topic was in May when the first ops page was ported to v3, back before the Beer Festival and the server patching work.
Clustering Let's Encrypt with Apache
2019-06-17 - Progress - Tony Finch
A few months ago I wrote about bootstrapping Let's Encrypt on Debian. I am now using Let's Encrypt certificates on the live DNS web servers.
Clustering
I have a smallish number of web servers (currently 3) and a smallish number of web sites (also about 3). I would like any web server to be able to serve any site, and dynamically change which site is on which server for failover, deployment canaries, etc.
If server 1 asks Let's Encrypt for a certificate for site A, but site A is currently hosted on server 0, the validation request will not go to server 1 so it won't get the correct response. It will fail unless server 0 helps server 1 to validate certificate requests from Let's Encrypt.
Validation servers
I considered various ways that my servers could co-operate to get certificates, but they all required extra machinery for authentication and access control that I don't currently have, and which would be tricky and important to get right.
However, there is a simpler option based on HTTP redirects. Thanks to Malcolm Scott for reminding me that ACME http-01 validation requests follow redirects! The Let's Encrypt integration guide mentions this under "picking a challenge type" and "central validation servers".
Decentralized validation
Instead of redirecting to a central validation server, a small web server cluster can co-operate to validate certificates. It goes like this:
server 1 requests a cert for site A
Let's Encrypt asks site A for the validation response, but this request goes to server 0
server 0 discovers it has no response, so it speculatively replies with a 302 redirect to one of the other servers
Let's Encrypt asks the other server for the validation response; after one or two redirects it will hit server 1 which does have the response
This is kind of gross, because it turns 404 "not found" errors into 302 redirect loops. But that should not happen in practice.
Apache mod_rewrite
My configuration to do this is a few lines of mod_rewrite. Yes, this doesn't help with the "kind of gross" aspect of this setup, sorry!
The rewrite runes live in a catch-all port 80 <VirtualHost> which
redirects everything (except for Let's Encrypt) to https. I am not
using the dehydrated-apache2 package any more; instead I have copied
its <Directory> section that tells Apache it is OK to serve
dehydrated's challenge responses.
I use Ansible's Jinja2 template module to install the
configuration and fill in a couple of variables: as usual,
{{inventory_hostname}} is the server the file is installed on, and
in each server's host_vars file I set {{next_acme_host}} to the
next server in the loop. The last server redirects to the first one,
like web0 -> web1 -> web2 -> web0. These are all server host names,
not virtual hosts or web site names.
Code
<VirtualHost *:80>
ServerName {{inventory_hostname}}
RewriteEngine on
# https everything except acme-challenges
RewriteCond %{REQUEST_URI} !^/.well-known/acme-challenge/
RewriteRule ^ https://%{SERVER_NAME}%{REQUEST_URI} [L,R=301]
# serve files that exist
RewriteCond /var/lib/dehydrated/acme-challenges/$1 -f
RewriteRule ^/.well-known/acme-challenge/(.*) \
/var/lib/dehydrated/acme-challenges/$1 [L]
# otherwise, try alternate server
RewriteRule ^ http://{{next_acme_host}}%{REQUEST_URI} [R=302]
</VirtualHost>
<Directory /var/lib/dehydrated/acme-challenges/>
Options FollowSymlinks
Options -Indexes
AllowOverride None
Require all granted
</Directory>
First ops page ported
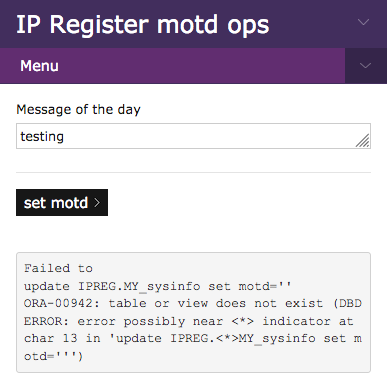
2019-05-15 - Progress - Tony Finch
Yesterday I reached a milestone: I have ported the first "ops" page from the old IP Register web user interface on Jackdaw to the new one that will live on the DNS web servers. It's a trivial admin page for setting the message of the day, but it demonstrates that the infrastructure is (mostly) done.
Security checks
I have spent the last week or so trying to get from a proof of concept to something workable. Much of this work has been on the security checks. The old UI has:
Cookie validation (for Oracle sessions)
Raven authentication
TOTP authentication for superusers
Second cookie validaion for TOTP
CSRF checks
There was an awkward split between the Jackdaw framework and the ipreg-specific parts which meant I needed to add a second cookie when I added TOTP authentication.
In the new setup I have upgraded the cookie to modern security levels, and it handles both Oracle and TOTP session state.
my @cookie_attr = (
-name => '__Host-Session',
-path => '/',
-secure => 1,
-httponly => 1,
-samesite => 'strict',
);
The various "middleware" authentication components have been split out of the main HTTP request handler so that the overall flow is much easier to see.
State objects
There is some fairly tricky juggling in the old code between:
CGI request object
WebIPDB HTTP request handler object
IPDB database handle wrapper
Raw DBI handle
The CGI object is gone. The mod_perl Apache2 APIs are sufficient
replacements, and the HTML generation functions are being
replaced by mustache templates. (Though there is some programmatic
form generation in table_ops that might be awkward!)
I have used Moo roles to mixin the authentication middleware bits to the main request handler object, which works nicely. I might do the same for the IPDB object, though that will require some refactoring of some very old skool OO perl code.
Next
The plan is to port the rest of the ops pages as directly as possible. There is going to be a lot of refactoring, but it will all be quite superficial. The overall workflow is going to remain the same, just more purple.
Oracle connection timeouts
2019-05-07 - Progress - Tony Finch
Last week while I was beating mod_perl code into shape, I happily
deleted a lot of database connection management code that I had
inherited from Jackdaw's web server. Today I had to put it all back
again.
Apache::DBI
There is a neat module called Apache::DBI which hooks mod_perl
and DBI together to provide a transparent connection cache: just throw
in a use statement, throw out dozens of lines of old code, and you
are pretty much done.
Connection hangs
Today the clone of Jackdaw that I am testing against was not available (test run for some maintenance work tomorrow, I think) and I found that my dev web server was no longer responding. It started OK but would not answer any requests. I soon worked out that it was trying to establish a database connection and waiting at least 5 minutes (!) before giving up.
DBI(3pm) timeouts
There is a long discussion about timeouts in the DBI documentation which specifically mentions DBD::Oracle as a problem case, with some lengthy example code for implementing a timeout wrapper around DBI::connect.
This is a terrible documentation anti-pattern. Whenever I find myself giving lengthy examples of how to solve a problem I take it as a whacking great clue that the code should be fixed so the examples can be made a lot easier.
In this case, DBI should have connection timeouts as standard.
Sys::SigAction
If you read past the examples in DBI(3pm) there's a reference to a more convenient module which provides a timeout wrapper that can be used like this:
if (timeout_call($connect_timeout, sub {
$dbh = DBI->connect(@connect_args);
moan $DBI::errstr unless $dbh;
})) {
moan "database connection timed out";
}
Undelete
The problem is that there isn't a convenient place to put this timeout code where it should be, so that Apache::DBI can use it transparently.
So I resurrected Jackdaw's database connection cache. But not exacly - I looked through it again and I could not see any extra timeout handling code. My guess is that hung connections can't happen if the database is on the same machine as the web server.
Reskinning IP Register
2019-05-01 - Progress - Tony Finch
At the end of the item about Jackdaw and Raven I mentioned that when the web user interface moves off Jackdaw it will get a reskin.
The existing code uses Perl CGI functions for rendering the HTML, with no styling at all. I'm replacing this with mustache templates using the www.dns.cam.ac.uk Project Light framework. So far I have got the overall navigation structure working OK, and it's time to start putting forms into the pages.
I fear this reskin is going to be disappointing, because although it's
superficially quite a lot prettier, the workflow is going to be the
same - for example, the various box_ops etc. links in the existing
user interface become Project Light local navigation tabs in the new
skin. And there are still going to be horrible Oracle errors.
Jackdaw and Raven
2019-04-16 - Progress - Tony Finch
I've previously written about authentication and access control in the IP Register database. The last couple of weeks I have been reimplementing some of it in a dev version of this DNS web server.
Bootstrapping Let's Encrypt on Debian
2019-03-15 - Progress - Tony Finch
I've done some initial work to get the Ansible playbooks for our DNS systems working with the development VM cluster on my workstation. At this point it is just for web-related experimentation, not actual DNS servers.
Of course, even a dev server needs a TLS certificate, especially because these experiments will be about authentication. Until now I have obtained certs from the UIS / Jisc / QuoVadis, but my dev server is using Let's Encrypt instead.
Chicken / egg
In order to get a certificate from Let's Encrypt using the http-01
challenge, I need a working web server. In order to start the web
server with its normal config, I need a certificate. This poses a bit
of a problem!
Snakeoil
My solution is to install Debian's ssl-cert package, which creates a
self-signed certificate. When the web server does not yet have a
certificate (if the QuoVadis cert isn't installed, or dehydrated has
not been initialized), Ansible temporarily symlinks the self-signed
cert for use by Apache, like this:
- name: check TLS certificate exists
stat:
path: /etc/apache2/keys/tls-web.crt
register: tls_cert
- when: not tls_cert.stat.exists
name: fake TLS certificates
file:
state: link
src: /etc/ssl/{{ item.src }}
dest: /etc/apache2/keys/{{ item.dest }}
with_items:
- src: certs/ssl-cert-snakeoil.pem
dest: tls-web.crt
- src: certs/ssl-cert-snakeoil.pem
dest: tls-chain.crt
- src: private/ssl-cert-snakeoil.key
dest: tls.pem
ACME dehydrated boulders
The dehydrated and dehydrated-apache2 packages need a little
configuration. I needed to add a cron job to renew the certificate, a
hook script to reload apache when the cert is renewed, and tell it
which domains should be in the cert. (See below for details of these
bits.)
After installing the config, Ansible initializes dehydrated if
necessary - the creates check stops Ansible from running
dehydrated again after it has created a cert.
- name: initialize dehydrated
command: dehydrated -c
args:
creates: /var/lib/dehydrated/certs/{{inventory_hostname}}/cert.pem
Having obtained a cert, the temporary symlinks get overwritten with links to the Let's Encrypt cert. This is very similar to the snakeoil links, but without the existence check.
- name: certificate links
file:
state: link
src: /var/lib/dehydrated/certs/{{inventory_hostname}}/{{item.src}}
dest: /etc/apache2/keys/{{item.dest}}
with_items:
- src: cert.pem
dest: tls-web.crt
- src: chain.pem
dest: tls-chain.crt
- src: privkey.pem
dest: tls.pem
notify:
- restart apache
After that, Apache is working with a proper certificate!
Boring config details
The cron script chatters into syslog, but if something goes wrong it should trigger an email (tho not a very informative one).
#!/bin/bash set -eu -o pipefail ( dehydrated --cron dehydrated --cleanup ) | logger --tag dehydrated --priority cron.info
The hook script only needs to handle one of the cases:
#!/bin/bash
set -eu -o pipefail
case "$1" in
(deploy_cert)
apache2ctl configtest &&
apache2ctl graceful
;;
esac
The configuration needs a couple of options added:
- copy:
dest: /etc/dehydrated/conf.d/dns.sh
content: |
EMAIL="hostmaster@cam.ac.uk"
HOOK="/etc/dehydrated/hook.sh"
The final part is to tell dehydrated the certificate's domain name:
- copy:
content: "{{inventory_hostname}}\n"
dest: /etc/dehydrated/domains.txt
For production, domains.txt needs to be a bit more complicated. I
have a template like the one below. I have not yet deployed it; that
will probably wait until the cert needs updating.
{{hostname}} {% if i_am_www %} www.dns.cam.ac.uk dns.cam.ac.uk {% endif %}
KSK rollover project status
2019-02-07 - Progress- Future - Tony Finch
I have spent the last week working on DNSSEC key rollover automation in BIND. Or rather, I have been doing some cleanup and prep work. With reference to the work I listed in the previous article...
Done
Stop BIND from generating SHA-1 DS and CDS records by default, per RFC 8624
Teach
dnssec-checkdsabout CDS and CDNSKEY
Started
- Teach
superglueto use CDS/CDNSKEY records, with similar logic todnssec-checkds
The "similar logic" is implemented in dnssec-dsfromkey, so I don't
actually have to write the code more than once. I hope this will also
be useful for other people writing similar tools!
Some of my small cleanup patches have been merged into BIND. We are currently near the end of the 9.13 development cycle, so this work is going to remain out of tree for a while until after the 9.14 stable branch is created and the 9.15 development cycle starts.
Next
So now I need to get to grips with dnssec-coverage and dnssec-keymgr.
Simple safety interlocks
The purpose of the dnssec-checkds improvements is so that it can be
used as a safety check.
During a KSK rollover, there are one or two points when the DS records in the parent need to be updated. The rollover must not continue until this update has been confirmed, or the delegation can be broken.
I am using CDS and CDNSKEY records as the signal from the key
management and zone signing machinery for when DS records need to
change. (There's a shell-style API in dnssec-dsfromkey -p, but that
is implemented by just reading these sync records, not by looking into
the guts of the key management data.) I am going to call them "sync
records" so I don't have to keep writing "CDS/CDNSKEY"; "sync" is also
the keyword used by dnssec-settime for controlling these records.
Key timing in BIND
The dnssec-keygen and dnssec-settime commands (which are used by
dnssec-keymgr) schedule when changes to a key will happen.
There are parameters related to adding a key: when it is published in the zone, when it becomes actively used for signing, etc. And there are parameters related to removing a key: when it becomes inactive for signing, when it is deleted from the zone.
There are also timing parameters for publishing and deleting sync records. These sync times are the only timing parameters that say when we must update the delegation.
What can break?
The point of the safety interlock is to prevent any breaking key changes from being scheduled until after a delegation change has been confirmed. So what key timing events need to be forbidden from being scheduled after a sync timing event?
Events related to removing a key are particularly dangerous. There are some cases where it is OK to remove a key prematurely, if the DS record change is also about removing that key, and there is another working key and DS record throughout. But it seems simpler and safer to forbid all removal-related events from being scheduled after a sync event.
However, events related to adding a key can also lead to nonsense. If we blindly schedule creation of new keys in advance, without verifying that they are also being properly removed, then the zone can accumulate a ridiculous number of DNSKEY records. This has been observed in the wild surprisingly frequently.
A simple rule
There must be no KSK changes of any kind scheduled after the next sync event.
This rule applies regardless of the flavour of rollover (double DS, double KSK, algorithm rollover, etc.)
Applying this rule to BIND
Whereas for ZSKs, dnssec-coverage ensures rollovers are planned for
some fixed period into the future, for KSKs, it must check correctness
up to the next sync event, then ensure nothing will occur after that point.
In dnssec-keymgr, the logic should be:
If the current time is before the next sync event, ensure there is key coverage until that time and no further.
If the current time is after all KSK events, use
dnssec-checkdsto verify the delegation is in sync.If
dnssec-checkdsreports an inconsistency and we are within some sync interval dictated by the rollover policy, do nothing while we wait for the delegation update automation to work.If
dnssec-checkdsreports an inconsistency and the sync interval has passed, report an error because operator intervention is required to fix the failed automation.If
dnssec-checkdsreports everything is in sync, schedule keys up to the next sync event. The timing needs to be relative to this point in time, since any delegation update delays can make it unsafe to schedule relative to the last sync event.
Caveat
At the moment I am still not familiar with the internals of
dnssec-coverage and dnssec-keymgr so there's a risk that I might
have to re-think these plans. But I expect this simple safety rule
will be a solid anchor that can be applied to most DNSSEC key
management scenarios. (However I have not thought hard enough about
recovery from breakage or compromise.)
Superglue with WebDriver
2019-01-25 - Progress - Tony Finch
Earlier this month I wrote notes on some initial experiments in browser automation with WebDriver. The aim is to fix my superglue DNS delegation update scripts to work with currently-supported tools.
In the end I decided to rewrite the superglue-janet script in Perl,
since most of superglue is already Perl and I would like to avoid
rewriting all of it. This is still work in progress; superglue is
currently an unusable mess, so I don't recommend looking at it right
now :-)
My WebDriver library
Rather than using an off-the-shelf library, I have a very thin layer (300 lines of code, 200 lines of docs) that wraps WebDriver HTTP+JSON calls in Perl subroutines. It's designed for script-style usage, so I can write things like this (quoted verbatim):
# Find the domain's details page.
click '#commonActionsMenuLogin_ListDomains';
fill '#MainContent_tbDomainNames' => $domain,
'#MainContent_ShowReverseDelegatedDomains' => 'selected';
click '#MainContent_btnFilter';
This has considerably less clutter than the old PhantomJS / CasperJS code!
Asyncrony
I don't really understand the concurrency model between the WebDriver server and the activity in the browser. It appears to be remarkably similar to the way CasperJS behaved, so I guess it is related to the way JavaScript's event loop works (and I don't really understand that either).
The upshot is that in most cases I can click on a link, and the
WebDriver response comes back after the new page has loaded. I can
immediately interact with the new page, as in the code above.
However there are some exceptions.
On the JISC domain registry web site there are a few cases where selecting from a drop-down list triggers some JavaScript that causes a page reload. The WebDriver request returns immediately, so I have to manually poll for the page load to complete. (This also happened with CasperJS.) I don't know if there's a better way to deal with this than polling...
The WebDriver spec
I am not a fan of the WebDriver protocol specification. It is written as a description of how the code in the WebDriver server / browser behaves, written in spaghetti pseudocode.
It does not have any abstract syntax for JSON requests and responses - no JSON schema or anything like that. Instead, the details of parsing requests and constructing responses are interleaved with details of implementing the semantics of the request. It is a very unsafe style.
And why does the WebDriver spec include details of how to HTTP?
Next steps
This work is part of two ongoing projects:
I need to update all our domain delegations to complete the server renaming.
I need automated delegation updates to support automated DNSSEC key rollovers.
So I'm aiming to get superglue into a usable state, and hook it up
to BIND's dnssec-keymgr.
Preserving dhcpd leases across reinstalls
2019-01-14 - Progress - Tony Finch
(This is an addendum to December's upragde notes.)
I have upgraded
the IP Register DHCP servers
twice this year. In February they were upgraded from Ubuntu 12.04 LTS
to 14.04 LTS, to cope with 12.04's end of life, and to merge their
setup into the main ipreg git repository (which is why the target
version was so old). So their setup was fairly tidy before the Debian
9 upgrade.
Statefulness
Unlike most of the IP Register systems, the dhcp servers are stateful.
Their dhcpd.leases files must be preserved across reinstalls.
The leases file is a database (in the form of a flat text file in ISC
dhcp config file format) which closely matches the state of the network.
If it is lost, the server no longer knows about IP addresses in use by existing clients, so it can issue duplicate addresses to new clients, and hilarity will ensue!
So, just before rebuilding a server, I have to stop the dhcpd and take a copy of the leases file. And before the dhcpd is restarted, I have to copy the leases file back into place.
This isn't something that happens very often, so I have not automated it yet.
Bad solutions
In February, I hacked around with the Ansible playbook to ensure the dhcpd was not started before I copied the leases file into place. This is an appallingly error-prone approach.
Yesterday, I turned that basic idea into an Ansible variable that controls whether the dhcpd is enabled. This avoids mistakes when fiddling with the playbook, but it is easily forgettable.
Better solution
This morning I realised a much neater way is to disable the entire dhcpd role if the leases file doesn't exist. This prevents the role from starting the dhcpd on a newly reinstalled server before the old leases file is in place. After the server is up, the check is a no-op.
This is a lot less error-prone. The only requirement for the admin is
knowledge about the importance of preserving dhcpd.leases...
Further improvements
The other pitfall in my setup is that monit will restart dhcpd if
it is missing, so it isn't easy to properly stop it.
My dhcpd_enabled Ansible variable takes care of this, but I think it
would be better to make a special shutdown playbook, which can also
take a copy of the leases file.
Review of 2018
2019-01-11 - Progress - Tony Finch
Some notes looking back on what happened last year...
Stats
1457 commits
4035 IP Register / MZS support messages
5734 cronspam messages
Projects
New DNS web site (Feb, Mar, Jun, Sep, Oct, Nov)
This was a rather long struggle with a lot of false starts, e.g. February / March finding that Perl Template Toolkit was not very satisfactory; realising after June that the server naming and vhost setup was unhelpful.
End result is quite pleasing
IP Register API extensions (Aug)
API access to
xlist_opsMWS3 API generalized for other UIS services
Now in active use by MWS, Drupal Falcon, and to a lesser extent by the HPC OpenStack cluster and the new web Traffic Managers. When old Falcon is wound down we will be able to eliminate Gossamer!
Server upgrade / rename (Dec)
Lots of Ansible review / cleanup. Satisfying.
Future of IP Register
Prototype setup for PostgreSQL replication using
repmgr(Jan)Prototype infrastructure for JSON-RPC API in Typescript (April, May)
Maintenance
DHCP servers upgraded to match rest of IP Register servers (Feb)
DNS servers upgraded to BIND 9.12, with some
serve-stalerelated problems. (March)Local patches all now incorporated upstream :-)
git.uis continues, hopefully not for much longer
IETF
Took over as the main author of draft-ietf-dnsop-aname. This work is ongoing.
Received thanks in RFC 8198 (DNSSEC negative answer synthesis), RFC 8324 (DNS privacy), RFC 8482 (minimal ANY responses), RFC 8484 (DNS-over-HTTPS).
Open Source
Ongoing maintenance of
regpg. This has stabilized and reached a comfortable feature plateau.Created
doh101, a DNS-over-TLS and DNS-over-HTTPS proxy.Initial prototype in March at the IETF hackathon.
Revamped in August to match final IETF draft.
Deployed in production in September.
Fifteen patches committed to BIND9.
CVE-2018-5737; extensive debugging work on the
serve-stalefeature.Thanked by ISC.org in their annual review.
Significant clean-up and enhancement of my qp trie data structure, used by Knot DNS. This enabled much smaller memory usage during incremental zone updates.
https://gitlab.labs.nic.cz/knot/knot-dns/issues/591
What's next?
Update
supergluedelegation maintenance script to match the current state of the world. Hook it in todnssec-keymgrand get automatic rollovers working.Rewrite draft-ietf-dnsop-aname again, in time for IETF104 in March.
Server renumbering, and xfer/auth server split, and anycast. When?
Port existing ipreg web interface off Jackdaw.
Port database from Oracle on Jackdaw to PostgreSQL on my servers.
Develop new API / UI.
Re-do provisioning system for streaming replication from database to DNS.
Move MZS into IP Register database.
Notes on web browser automation
2019-01-08 - Progress - Tony Finch
I spent a few hours on Friday looking in to web browser automation. Here are some notes on what I learned.
Context
I have some old code called superglue-janet which drives the JISC / JANET / UKERNA domain registry web site. The web site has some dynamic JavaScript behaviour, and it looks to me like the browser front-end is relatively tightly coupled to the server back-end in a way that I expected would make reverse engineering unwise. So I decided to drive the web site using browser automation tools. My code is written in JavaScript, using PhantomJS (a headless browser based on QtWebKit) and CasperJS (convenience utilities for PhantomJS).
Rewrite needed
PhantomJS is now deprecated, so the code needs a re-work. I also want to use TypeScript instead, where I would previously have used JavaScript.
Current landscape
The modern way to do things is to use a full-fat browser in headless mode and control it using the standard WebDriver protocol.
For Firefox this means using the geckodriver proxy which is a Rust program that converts the WebDriver JSON-over-HTTP protocol to Firefox's native Marionette protocol.
[Aside: Marionette is a full-duplex protocol that exchanges JSON messages prefixed by a message length. It fits into a similar design space to Microsoft's Language Server Protocol, but LSP uses somewhat more elaborate HTTP-style framing and JSON-RPC message format. It's kind of a pity that Marionette doesn't use JSON-RPC.]
The WebDriver protocol came out of the Selenium browser automation project where earlier (incompatible) versions were known as the JSON Wire Protocol.
What I tried out
I thought it would make sense to write the WebDriver client in TypeScript. The options seemed to be:
selenium-webdriver, which has Selenium's bindings for node.js. This involves a second proxy written in Java which goes between node and geckodriver. I did not like the idea of a huge wobbly pile of proxies.
webdriver.io aka wdio, a native node.js WebDriver client. I chose to try this, and got it going fairly rapidly.
What didn't work
I had enormous difficulty getting anything to work with wdio and TypeScript. It turns out that the wdio typing was only committed a couple of days before my attempt, so I had accidentally found myself on the bleeding edge. I can't tell whether my failure was due to lack of documentation or brokenness in the type declarations...
What next
I need to find a better WebDriver client library. The wdio framework is very geared towards testing rather than general automation (see the wdio "getting started" guide for example) so if I use it I'll be talking to its guts rather than the usual public interface. And it won't be very stable.
I could write it in Perl but that wouldn't really help to reduce the amount of untyped code I'm writing :-)
The missing checklist
2019-01-07 - Progress - Tony Finch
Before I rename/upgrade any more servers, this is the checklist I should have written last month...
For rename
Ensure both new and old names are in the DNS
Rename the host in
ipreg/ansible/bin/make-inventoryand run the scriptRun
ipreg/ansible/bin/ssh-knowhoststo update~/.ssh/known_hostsRename
host_vars/$SERVERand adjust the contents to match a previously renamed server (mutatis mutandis)For recursive servers, rename the host in
ipreg/ansible/roles/keepalived/files/vrrp-scriptandipreg/ansible/inventory/dynamic
For both
- Ask
infra-sas@uisto do the root privilege parts of the netboot configuration - rename and/or new OS version as required
For upgrade
For DHCP servers, save a copy of the leases file by running:
ansible-playbook dhcpd-shutdown-save-leases.yml \ --limit $SERVERRun the
preseed.ymlplaybook to update the unprivileged parts of the netboot configReboot the server, tell it to netboot and do a preseed install
Wait for that to complete
For DHCP servers, copy the saved leases file to the server.
Then run:
ANSIBLE_SSH_ARGS=-4 ANSIBLE_HOST_KEY_CHECKING=False \ ansible-playbook -e all=1 --limit $SERVER main.yml
For rename
Update the rest of the cluster's view of the name
git push ansible-playbook --limit new main.yml
Notes on recent DNS server upgrades
2019-01-02 - Progress - Tony Finch
I'm now most of the way through the server upgrade part of the rename / renumbering project. This includes moving the servers from Ubuntu 14.04 "Trusty" to Debian 9 "Stretch", and renaming them according to the new plan.
Done:
Live and test web servers, which were always Stretch, so they served as a first pass at getting the shared parts of the Ansible playbooks working
Live and test primary DNS servers
Live x 2 and test x 2 authoritative DNS servers
One recursive server
To do:
Three other recursive servers
Live x 2 and test x 1 DHCP servers
Here are a few notes on how the project has gone so far.
Postcronspam
2018-11-30 - Progress - Tony Finch
This is a postmortem of an incident that caused a large amount of cronspam, but not an outage. However, the incident exposed a lot of latent problems that need addressing.
Description of the incident
I arrived at work late on Tuesday morning to find that the DHCP
servers were sending cronspam every minute from monit. monit
thought dhcpd was not working, although it was.
A few minutes before I arrived, a colleague had run our Ansible playbook to update the DHCP server configuration. This was the trigger for the cronspam.
Cause of the cronspam
We are using monit as a basic daemon supervisor for our critical
services. The monit configuration doesn't have an "include" facility
(or at least it didn't when we originally set it up) so we are using
Ansible's "assemble" feature to concatenate configuration file
fragments into a complete monit config.
The problem was that our Ansible setup didn't have any explicit
dependencies between installing monit config fragments and
reassembling the complete config and restarting monit.
Running the complete playbook caused the monit config to be
reassembled, so an incorrect but previously inactive config fragment
was activated, causing the cronspam.
Origin of the problem
How was there an inactive monit config fragment on the DHCP servers?
The DHCP servers had an OS upgrade and reinstall in February. This was
when the spammy broken monit config fragment was written.
What were the mistakes at that time?
The config fragment was not properly tested. A good
monitconfig is normally silent, but in this case we didn't check that it sent cronspam when things are broken, whoch would have revealed that the config fragment was not actually installed properly.The Ansible playbook was not verified to be properly idempotent. It should be possible to wipe a machine and reinstall it with one run of Ansible, and a second run should be all green. We didn't check the second run properly. Check mode isn't enough to verify idempotency of "assemble".
During routine config changes in the nine months since the servers were reinstalled, the usual practice was to run the DHCP-specific subset of the Ansible playbook (because that is much faster) so the bug was not revealed.
Deeper issues
There was a lot more anxiety than there should have been when debugging this problem, because at the time the Ansible playbooks were going through a lot of churn for upgrading and reinstalling other servers, and it wasn't clear whether or not this had caused some unexpected change.
This gets close to the heart of the matter:
- It should always be safe to check out and run the Ansible playbook against the production systems, and expect that nothing will change.
There are other issues related to being a (nearly) solo developer, which makes it easier to get into bad habits. The DHCP server config has the most contributions from colleagues at the moment, so it is not really surprising that this is where we find out the consequences of the bad habits of soloists.
Resolutions
It turns out that monit and dhcpd do not really get along. The
monit UDP health checker doesn't work with DHCP (which was the cause
of the cronspam) and monit's process checker gets upset by dhcpd
being restarted when it needs to be reconfigured.
The monit DHCP UDP checker has been disabled; the process checker
needs review to see if it can be useful without sending cronspam on
every reconfig.
There should be routine testing to ensure the Ansible playbooks committed to the git server run green, at least in check mode. Unfortunately it's risky to automate this because it requires root access to all the servers; at the moment root access is restricted to admins in person.
We should be in the habit of running the complete playbook on all the servers (e.g. before pushing to the git server), to detect any differences between check mode and normal (active) mode. This is necessary for Ansible tasks that are skipped in check mode.
Future work
This incident also highlights longstanding problems with our low bus protection factor and lack of automated testing. The resolutions listed above will make some small steps to improve these weaknesses.
DNS-OARC and RIPE
2018-10-23 - Progress - Tony Finch
Last week I visited Amsterdam for a bunch of conferences. The 13th and 14th was the joint DNS-OARC and CENTR workshop, and 15th - 19th was the RIPE77 meeting.
I have a number of long-term projects which can have much greater success within the University and impact outside the University by collaborating with people from other organizations in person. Last week was a great example of that, with significant progress on CDS (which I did not anticipate!), ANAME, and DNS privacy, which I will unpack below.
DNS-over-TLS snapshot
2018-10-10 - Progress - Tony Finch
Some quick stats on how much the new DNS-over-TLS service is being used:
At the moment (Wednesday mid-afternoon) we have about
29,000 - 31,000 devices on the wireless network
3900 qps total on both recursive servers
about 15 concurrent DoT clients (s.d. 4)
about 7qps DoT (s.d. 5qps)
5s TCP idle timeout
6.3s mean DoT connection time (s.d. 4s - most connections are just over 5s, they occasionally last as long as 30s; mean and s.d. are not a great model for this distribution)
DoT connections very unbalanced, 10x fewer on 131.111.8.42 than on 131.111.12.20
The rule of thumb that number of users is about 10x qps suggests that we have about 70 Android Pie users, i.e. about 0.2% of our userbase.
IPv6 DAD-die issues
2018-03-26 - Progress - Tony Finch
Here's a somewhat obscure network debugging tale...
Deprocrastinating
2018-02-16 - Progress - Tony Finch
I'm currently getting several important/urgent jobs out of the way so that I can concentrate on the IP Register database project.
An interesting bug in BIND
2018-01-12 - Progress - Tony Finch
(This item isn't really related to progress towards a bright shiny future, but since I'm blogging here I might as well include other work-related articles.)
This week I have been helping
Mark Andrews and Evan Hunt
to track down a bug in BIND9. The problem manifested as named
occasionally failing to re-sign a DNSSEC zone; the underlying cause
was access to uninitialized memory.
It was difficult to pin down, partly because there is naturally a lot of nondeterminism in uninitialized memory bugs, but there is also a lot of nondeterminism in the DNSSEC signing process, and it is time-dependent so it is hard to re-run a failure case, and normally the DNSSEC signing process is very slow - three weeks to process a zone, by default.
Timeline
Oct 9 - latent bug exposed
Nov 12 - first signing failure
I rebuild and restart my test DNS server quite frequently, and the bug is quite rare, which explains why it took so long to appear.
Nov 18 - Dec 6 - Mark fixes several signing-related bugs
Dec 28 - another signing failure
Jan 2 - I try adding some debugging diagnostics, without success
Jan 9 - more signing failures
Jan 10 - I make the bug easier to reproduce
Mark and Evan identify a likely cause
Jan 11 - I confirm the cause and fix
The debugging process
The incremental re-signing code in named is tied into BIND's core
rbtdb data structure (the red-black tree database). This is tricky
code that I don't understand, so I mostly took a black-box approach to
try to reproduce it.
I started off by trying to exercise the signing code harder. I set up a test zone with the following options:
# signatures valid for 1 day (default is 30 days)
# re-sign 23 hours before expiry
# (whole zone is re-signed every hour)
sig-validity-interval 1 23;
# restrict the size of a batch of signing to examine
# at most 10 names and generate at most 2 signatures
sig-signing-nodes 10;
sig-signing-signatures 2;
I also populated the zone with about 500 records (not counting DNSSEC records) so that several records would get re-signed each minute.
This helped a bit, but I often had to wait a long time before it went
wrong. I wrote a script to monitor the zone using rndc zonestatus, so
I could see if the "next resign time" matches the zone's earliest
expiring signature.
There was quite a lot of flailing around trying to exercise the code harder, by making the zone bigger and changing the configuration options, but I was not successful at making the bug appear on demand.
To make it churn faster, I used dnssec-signzone to construct a version
of the zone in which all the signatures expire in the next few minutes:
rndc freeze test.example
dig axfr test.example | grep -v RRSIG |
dnssec-signzone -e now+$((86400 - 3600 - 200)) \
-i 3600 -j 200 \
-f signed -o test.example /dev/stdin
rm -f test.example test.example.jnl
mv signed test.example
# re-load the zone
rndc thaw test.example
# re-start signing
rndc sign test.example
I also modified BIND's re-signing co-ordination code; normally each batch will re-sign any records that are due in the next 5 seconds; I reduced that to 1 second to keep batch sizes small, on the assumption that more churn would help - which it did, a little bit.
But the bug still took a random amount of time to appear, sometimes within a few minutes, sometimes it would take ages.
Finding the bug
Mark (who knows the code very well) took a bottom-up approach; he ran
named under valgrind which identified an access to uninitialized
memory. (I don't know what led Mark to try valgrind - whether he does
it routinely or whether he tried it just for this bug.)
Evan had not been able to reproduce the bug, but once the cause was identified it became clear where it came from.
The commit on the 9th October that exposed the bug was a change to BIND's memory management code, to stop it from deliberately filling newly-allocated memory with garbage.
Before this commit, the missing initialization was hidden by the memory fill, and the byte used to fill new allocations (0xbe) happened to have the right value (zero in the bottom bit) so the signer worked correctly.
Evan builds BIND in developer mode, which enables memory filling, which stopped him from being able to reproduce it.
Verifying the fix
I changed BIND to fill memory with 0xff which (if we were right) should provoke signing failures much sooner. And it did!
Then applying the one-character fix to remove the access to uninitialized memory made the signer work properly again.
Lessons learned
BIND has a lot of infrastructure that tries to make C safer to use, for instance:
Run-time assertions to ensure that internal APIs are used correctly;
Canary elements at the start of most objects to detect memory overruns;
bufferandregiontypes to prevent memory overruns;A memory management system that keeps statistics on memory usage, and helps to debug memory leaks and other mistakes.
The bug was caused by failing to use buffers well, and hidden by the
memory management system.
The bug occurred when initializing an rdataslab data structure, which
is an in-memory serialization of a set of DNS records. The records are
copied into the rdataslab in traditional C style, without using a
buffer. (This is most blatant when the code
manually serializes a 16 bit number
instead of using isc_buffer_putuint16.) This code is particularly
ancient which might explain the poor style; I think it needs
refactoring for safety.
It's ironic that the bug was hidden by the memory management code - it's
supposed to help expose these kinds of bug, not hide them! Nowadays, the
right approach would be to link to jemalloc or some other advanced
allocator, rather than writing a complicated wrapper around standard
malloc. However that wasn't an option when BIND9 development started.
Conclusion
Memory bugs are painful.
The first Oracle to PostgreSQL trial
2017-12-24 - Progress - Tony Finch
I have used ora2pg to do a quick export
of the IP Register database from Oracle to PostgreSQL. This export
included an automatic conversion of the table structure, and the
contents of the tables. It did not include the more interesting parts
of the schema such as the views, triggers, and stored procedures.
Oracle Instant Client
Before installing ora2pg, I had to install the Oracle client
libraries. These are not available in Debian, but Debian's ora2pg
package is set up to work with the following installation process.
Get the Oracle Instant Client RPMs
from Oracle's web site. This is a free download, but you will need to create an Oracle account.
I got the
basicliteRPM - it's about half the size of thebasicRPM and I didn't need full i18n. I also got thesqlplusRPM so I can talk to Jackdaw directly from my dev VMs.The
libdbd-oracle-perlpackage in Debian 9 (Stretch) requires Oracle Instant Client 12.1. I matched the version installed on Jackdaw, which is 12.1.0.2.0.Convert the RPMs to debs (I did this on my workstation)
$ fakeroot alien oracle-instantclient12.1-basiclite-12.1.0.2.0-1.x86_64.rpm $ fakeroot alien oracle-instantclient12.1-sqlplus-12.1.0.2.0-1.x86_64.rpm
Those packages can be installed on the dev VM, with
libaio1(which is required by Oracle Instant Client but does not appear in the package dependencies), andlibdbd-oracle-perlandora2pg.sqlplusneeds a wrapper script that sets environment variables so that it can find its libraries and configuration files. After some debugging I foud that although the documentation claims thatglogin.sqlis loaded from$ORACLE_HOME/sqlplus/admin/in fact it is loaded from$SQLPATH.To configure connections to Jackdaw, I copied
tnsnames.oraandsqlnet.orafroment.
Running ora2pg
By default, ora2pg exports the table definitions of the schema we
are interested in (i.e. ipreg). For the real conversion I intend to
port the schema manually, but ora2pg's automatic conversion is handy
for a quick trial, and it will probably be a useful guide to
translating the data type names.
The commands I ran were:
$ ora2pg --debug $ mv output.sql tables.sql $ ora2pg --debug --type copy $ mv output.sql rows.sql $ table-fixup.pl <tables.sql >fixed.sql $ psql -1 -f functions.sql $ psql -1 -f fixed.sql $ psql -1 -f rows.sql
The fixup script and SQL functions were necessary to fill in some gaps
in ora2pg's conversion, detailed below.
Compatibility problems
Oracle treats the empty string as equivalent to NULL but PostgreSQL does not.
This affects constraints on the
lanandmzonetables.The Oracle
substrfunction supports negative offsets which index from the right end of the string, but PostgreSQL does not.This affects subdomain constraints on the
unique_name,maildom, andservicetables. These constraints should be replaced by function calls rather than copies.The
ipregschema usesrawcolumns for IP addresses and prefixes;ora2pgconverted these tobytea.The
v6_prefixtable has a constraint that relies on implicit conversion fromrawto a hex string. PostgreSQL is stricter about types, so this expression needs to work onbyteadirectly.There are a number of cases where
ora2pgrepresented named unique constraints as unnamed constraints with named indexes. This unnecessarily exposes an implementation detail.There were a number of Oracle functions which PostgreSQL doesn't support (even with
orafce), so I implemented them in thefunctions.sqlfile.- regexp_instr()
- regexp_like()
- vzise()
Other gotchas
The
mzone_co,areader, andregistrartables reference theperstable in thejdawadmschema. These foreign key constraints need to be removed.There is a weird bug in
ora2pgwhich mangles the regex[[:cntrl:]]into[[cntrl:]]This is used several times in the
ipregschema to ensure that various fields are plain text. The regex is correct in the schema source and in theALL_CONSTRAINTStable on Jackdaw, which is why I think it is anora2pgbug.There's another weird bug where a
regexp_like(string,regex,flags)expression is converted tostring ~ regex, flagswhich is nonsense.There are other calls to
regexp_like()in the schema which do not get mangled in this way, but they have non-trivial string expressions whereas the broken one just has a column name.
Performance
The export of the data from Oracle and the import to PostgreSQL took an uncomfortably long time. The SQL dump file is only 2GB so it should be possible to speed up the import considerably.
How to get a preseed file into a Debian install ISO
2017-12-12 - Progress - Tony Finch
Goal: install a Debian VM from scratch, without interaction, and with a minimum of external dependencies (no PXE etc.) by putting a preseed file on the install media.
Sadly the documentation for how to do this is utterly appalling, so here's a rant.
Starting point
The Debian installer documentation, appendix B.
https://www.debian.org/releases/stable/amd64/apbs02.html.en
Some relevant quotes:
Putting it in the correct location is fairly straightforward for network preseeding or if you want to read the file off a floppy or usb-stick. If you want to include the file on a CD or DVD, you will have to remaster the ISO image. How to get the preconfiguration file included in the initrd is outside the scope of this document; please consult the developers' documentation for debian-installer.
Note there is no link to the developers' documentation.
If you are using initrd preseeding, you only have to make sure a file named preseed.cfg is included in the root directory of the initrd. The installer will automatically check if this file is present and load it.
For the other preseeding methods you need to tell the installer what file to use when you boot it. This is normally done by passing the kernel a boot parameter, either manually at boot time or by editing the bootloader configuration file (e.g.
syslinux.cfg) and adding the parameter to the end of the append line(s) for the kernel.
Note that we'll need to change the installer boot process in any case, in order to skip the interactive boot menu. But these quotes suggest that we'll have to remaster the ISO, to edit the boot parameters and maybe alter the initrd.
So we need to guess where else to find out how to do this.
Wiki spelunking
https://wiki.debian.org/DebianInstaller
This suggests we should follow https://wiki.debian.org/DebianCustomCD
or use simple-cdd.
simple-cdd
I tried simple-cdd but it failed messily.
It needs parameters to select the correct version (it defaults to Jessie) and a local mirror (MUCH faster).
$ time simple-cdd --dist stretch \
--debian-mirror http://ftp.uk.debian.org/debian
[...]
ERROR: missing required packages from profile default: less
ERROR: missing required packages from profile default: simple-cdd-profiles
WARNING: missing optional packages from profile default: grub-pc grub-efi popularity-contest console-tools console-setup usbutils acpi acpid eject lvm2 mdadm cryptsetup reiserfsprogs jfsutils xfsprogs debootstrap busybox syslinux-common syslinux isolinux
real 1m1.528s
user 0m34.748s
sys 0m1.900s
Sigh, looks like we'll have to do it the hard way.
Modifying the ISO image
Eventually I realise the hard version of making a CD image without
simple-cdd is mostly about custom package selections, which is not
something I need.
This article is a bit more helpful...
https://wiki.debian.org/DebianInstaller/Preseed
It contains a link to...
https://wiki.debian.org/DebianInstaller/Preseed/EditIso
That requires root privilege and is a fair amount of faff.
That page in turn links to...
https://wiki.debian.org/DebianInstaller/Modify
And then...
https://wiki.debian.org/DebianInstaller/Modify/CD
This has a much easier way of unpacking the ISO using bsdtar, and
instructions on rebuilding a hybrid USB/CD ISO using xorriso. Nice.
Most of the rest of the page is about changing package selections which we already determined we don't need.
Boot configuration
OK, so we have used bsdtar to unpack the ISO, and we can see various
boot-related files. We need to find the right ones to eliminate the
boot menu and add the preseed arguments.
There is no syslinux.cfg in the ISO so the D-I documentation's
example is distressingly unhelpful.
I first tried editing boot/grub/grub.cfg but that had no effect.
There are two boot mechanisms on the ISO, one for USB and one for
CD/DVD. The latter is in isolinux/isolinux.cfg.
Both must be edited (in similar but not identical ways) to get the effect I want regardless of the way the VM boots off the ISO.
Unpacking and rebuilding the ISO takes less than 3 seconds on my workstation, which is acceptably fast.
Ongoing DNSSEC work
2017-10-05 - Progress - Tony Finch
We reached a nice milestone today which I'm pretty chuffed about, so I wanted to share the good news. This is mostly of practical interest to the Computer Lab and Mathematics, since they have delegated DNSSEC signed zones, but I hope it is of interest to others as well.
I have a long-term background project to improve the way we manage our DNSSEC keys. We need to improve secure storage and backups of private keys, and updating public key digests in parent zones. As things currently stand it requires tricky and tedious manual work to replace keys, but it ought to be zero-touch automation.
We now have most of the pieces we need to support automatic key management.
regpg
For secure key storage and backup, we have a wrapper around GPG called
regpg which makes it easier to repeatably encrypt files to a managed set
of "recipients" (in GPG terminology). In this case the recipients are the
sysadmins and they are able to decrypt the DNS keys (and other secrets)
for deployment on new servers. With regpg the key management system will
be able to encrypt newly generated keys but not able to decrypt any other
secrets.
At the moment regpg is in use and sort-of available (at the link below)
but this is a temporary home until I have released it properly.
Edited to link to the regpg home page
dnssec-cds
There are a couple of aspects to DNSKEY management: scheduling the rollovers, and keeping delegations in sync.
BIND 9.11 has a tool called dnssec-keymgr which makes rollovers a lot
easier to manage. It needs a little bit of work to give it proper support
for delegation updates, but it's definitely the way of the future. (I
don't wholeheartedly recommend it in its current state.)
For synchronizing delegations, RFC 7344 describes special CDS and CDNSKEY records which a child zone can publish to instruct its parent to update the delegation. There's some support for the child side of this protocol in BIND 9.11, but it will be much more complete in BIND 9.12.
I've written dnssec-cds, an implementation of the parent side, which was
committed to BIND this morning. (Yay!) My plan is to use this tool for
managing our delegations to the CL and Maths. BIND isn't an easy codebase
to work with; the reason for implementing dnssec-cds this way is (I
hope) to encourage more organizations to deploy RFC 7344 support than I
could achieve with a standalone tool.
https://gitlab.isc.org/isc-projects/bind9/commit/ba37674d038cd34d0204bba105c98059f141e31e
Until our parent zones become enlightened to the ways of RFC 7344 (e.g. RIPE, JANET, etc.) I have a half-baked framework that wraps various registry/registrar APIs so that we can manage delegations for all our domains in a consistent manner. It needs some work to bring it up to scratch, probably including a rewrite in Python to make it more appealing.
Conclusion
All these pieces need to be glued together, and I'm not sure how long that will take. Some of this glue work needs to be done anyway for non-DNSSEC reasons, so I'm feeling moderately optimistic.
DNS DoS mitigation by patching BIND to support draft-ietf-dnsop-refuse-any
2016-02-05 - Progress - Tony Finch
Last weekend one of our authoritative name servers
(authdns1.csx.cam.ac.uk) suffered a series of DoS attacks which made
it rather unhappy. Over the last week I have developed a patch for
BIND to make it handle these attacks better.
The attack traffic
On authdns1 we provide off-site secondary name service to a number of
other universities and academic institutions; the attack targeted
imperial.ac.uk.
For years we have had a number of defence mechanisms on our DNS servers. The main one is response rate limiting, which is designed to reduce the damage done by DNS reflection / amplification attacks.
However, our recent attacks were different. Like most reflection / amplification attacks, we were getting a lot of QTYPE=ANY queries, but unlike reflection / amplification attacks these were not spoofed, but rather were coming to us from a lot of recursive DNS servers. (A large part of the volume came from Google Public DNS; I suspect that is just because of their size and popularity.)
My guess is that it was a reflection / amplification attack, but we were not being used as the amplifier; instead, a lot of open resolvers were being used to amplify, and they in turn were making queries upstream to us. (Consumer routers are often open resolvers, but usually forward to their ISP's resolvers or to public resolvers such as Google's, and those query us in turn.)
What made it worse
Because from our point of view the queries were coming from real resolvers, RRL was completely ineffective. But some other configuration settings made the attacks cause more damage than they might otherwise have done.
I have configured our authoritative servers to avoid sending large UDP packets which get fragmented at the IP layer. IP fragments often get dropped and this can cause problems with DNS resolution. So I have set
max-udp-size 1420; minimal-responses yes;
The first setting limits the size of outgoing UDP responses to an MTU which is very likely to work. (The ethernet MTU minus some slop for tunnels.) The second setting reduces the amount of information that the server tries to put in the packet, so that it is less likely to be truncated because of the small UDP size limit, so that clients do not have to retry over TCP.
This works OK for normal queries; for instance a cam.ac.uk IN MX query
gets a svelte 216 byte response from our authoritative servers but a
chubby 2047 byte response from our recursive servers which do not have
these settings.
But ANY queries blow straight past the UDP size limit: the attack
queries for imperial.ac.uk IN ANY got obese 3930 byte responses.
The effect was that the recursive clients retried their queries over TCP, and consumed the server's entire TCP connection quota. (Sadly BIND's TCP handling is not up to the standard of good web servers, so it's quite easy to nadger it in this way.)
draft-ietf-dnsop-refuse-any
We might have coped a lot better if we could have served all the attack traffic over UDP. Fortunately there was some pertinent discussion in the IETF DNSOP working group in March last year which resulted in draft-ietf-dnsop-refuse-any, "providing minimal-sized responses to DNS queries with QTYPE=ANY".
This document was instigated by Cloudflare, who have a DNS server architecture which makes it unusually difficult to produce traditional comprehensive responses to ANY queries. Their approach is instead to send just one synthetic record in response, like
cloudflare.net. HINFO ( "Please stop asking for ANY"
"See draft-jabley-dnsop-refuse-any" )
In the discussion, Evan Hunt (one of the BIND developers) suggested an alternative approach suitable for traditional name servers. They can reply to an ANY query by picking one arbitrary RRset to put in the answer, instead of all of the RRsets they have to hand.
The draft says you can use either of these approaches. They both allow an authoritative server to make the recursive server go away happy that it got an answer, and without breaking odd applications like qmail that foolishly rely on ANY queries.
I did a few small experiments at the time to demonstrate that it really would work OK in the real world (unlike some of the earlier proposals) and they are both pretty neat solutions (unlike some of the earlier proposals).
Attack mitigation
So draft-ietf-dnsop-refuse-any is an excellent way to reduce the damage caused by the attacks, since it allows us to return small UDP responses which reduce the downstream amplification and avoid pushing the intermediate recursive servers on to TCP. But BIND did not have this feature.
I did a very quick hack on Tuesday to strip down ANY responses, and I deployed it to our authoritative DNS servers on Wednesday morning for swift mitigation. But it was immediately clear that I had put my patch in completely the wrong part of BIND, so it would need substantial re-working before it could be more widely useful.
I managed to get back to the Patch on Thursday. The right place to put
the logic was in the fearsome query_find() which is
the top-level query handling function and nearly 2400 lines long! I
finished the first draft of the revised patch that afternoon (using
none of the code I wrote on Tuesday), and I spent Friday afternoon
debugging and improving it.
The result this patch which adds a minimal-qtype-any option. I'm currently running it on my toy nameserver, and I plan to deploy it to our production servers next week to replace the rough hack.
I have submitted the patch to ISC.org; hopefully something like it will be included in a future version of BIND. And it prompted a couple of questions about draft-ietf-dnsop-refuse-any that I posted to the DNSOP working group mailing list.
Cutting a zone with DNSSEC
2015-10-21 - Progress - Tony Finch
This week we will be delegating newton.cam.ac.uk (the Isaac Newton
Institute's domain) to the Faculty of Mathematics, who have been
running their own DNS since the very earliest days of Internet
connectivity in Cambridge.
Unlike most new delegations, the newton.cam.ac.uk domain already
exists and has a lot of records, so we have to keep them working
during the process. And for added fun, cam.ac.uk is signed with
DNSSEC, so we can't play fast and loose.
In the absence of DNSSEC, it is mostly OK to set up the new zone, get all the relevant name servers secondarying it, and then introduce the zone cut. During the rollout, some servers will be serving the domain from the old records in the parent zone, and other servers will serve the domain from the new child zone, which occludes the old records in its parent.
But this won't work with DNSSEC because validators are aware of zone cuts, and they check that delegations across cuts are consistent with the answers they have received. So with DNSSEC, the process you have to follow is fairly tightly constrained to be basically the opposite of the above.
The first step is to set up the new zone on name servers that are
completely disjoint from those of the parent zone. This ensures that a
resolver cannot prematurely get any answers from the new zone - they
have to follow a delegation from the parent to find the name servers
for the new zone. In the case of newton.cam.ac.uk, we are lucky that
the Maths name servers satisfy this requirement.
The second step is to introduce the delegation into the parent zone. Ideally this should propagate to all the authoritative servers promptly, using NOTIFY and IXFR.
(I am a bit concerned about DNSSEC software which does validation as a separate process after normal iterative resolution, which is most of it. While the delegation is propagating it is possible to find the delegation when resolving, but get a missing delegation when validating. If the validator is persistent at re-querying for the delegation chain it should be able to recover from this; but quick propagation minimizes the problem.)
After the delegation is present on all the authoritative servers, and
old data has timed out of caches, the new child zone can (if
necessary) be added to the parent zone's name servers. In our case the
central cam.ac.uk name servers and off-site secondaries also serve the
Maths zones, so this step normalizes the setup for newton.cam.ac.uk.
DNS server rollout report
2015-02-16 - Progress - Tony Finch
Last week I rolled out my new DNS servers. It was reasonably successful - a few snags but no showstoppers.
Recursive DNS rollout plan - and backout plan!
2015-01-30 - Progress - Tony Finch
The last couple of weeks have been a bit slow, being busy with email and DNS support, an unwell child, and surprise 0day. But on Wednesday I managed to clear the decks so that on Thursday I could get down to some serious rollout planning.
My aim is to do a forklift upgrade of our DNS servers - a tier 1 service - with negligible downtime, and with a backout plan in case of fuckups.
BIND patches as a byproduct of setting up new DNS servers
2015-01-17 - Progress - Tony Finch
On Friday evening I reached a BIG milestone in my project to replace Cambridge University's DNS servers. I finished porting and rewriting the dynamic name server configuration and zone data update scripts, and I was - at last! - able to get the new servers up to pretty much full functionality, pulling lists of zones and their contents from the IP Register database and the managed zone service, and with DNSSEC signing on the new hidden master.
There is still some final cleanup and robustifying to do, and checks to make sure I haven't missed anything. And I have to work out the exact process I will follow to put the new system into live service with minimum risk and disruption. But the end is tantalizingly within reach!
In the last couple of weeks I have also got several small patches into BIND.
Recursive DNS server failover with keepalived --vrrp
2015-01-09 - Progress - Tony Finch
I have got keepalived working on my recursive DNS servers, handling
failover for testdns0.csi.cam.ac.uk and testdns1.csi.cam.ac.uk. I
am quite pleased with the way it works.
Network setup for Cambridge's new DNS servers
2015-01-07 - Progress - Tony Finch
The SCCS-to-git project that I wrote about previously was the prelude to setting up new DNS servers with an entirely overhauled infrastructure.
Uplift from SCCS to git
2014-11-27 - Progress - Tony Finch
My current project is to replace Cambridge University's DNS servers. The first stage of this project is to transfer the code from SCCS to Git so that it is easier to work with.
Ironically, to do this I have ended up spending lots of time working with SCCS and RCS, rather than Git. This was mainly developing analysis and conversion tools to get things into a fit state for Git.
If you find yourself in a similar situation, you might find these tools helpful.
The early days of the Internet in Cambridge
2014-10-30 - Progress - Tony Finch
I'm currently in the process of uplifting our DNS development / operations repository from SCCS (really!) to git. This is not entirely trivial because I want to ensure that all the archival material is retained in a sensible way.
I found an interesting document from one of the oldest parts of the archive, which provides a good snapshot of academic computer networking in the UK in 1991. It was written by Tony Stonely, aka <ajms@cam.ac.uk>. AJMS is mentioned in RFC 1117 as the contact for Cambridge's IP address allocation. He was my manager when I started work at Cambridge in 2002, though he retired later that year.
The document is an email discussing IP connectivity for Cambridge's Institute of Astronomy. There are a number of abbreviations which might not be familiar...
- Coloured Book: the JANET protocol suite
- CS: the University Computing Service
- CUDN: the Cambridge University Data Network
- GBN: the Granta Backbone Network, Cambridge's duct and fibre infrastructure
- grey: short for Grey Book, the JANET email protocol
- IoA: the Institute of Astronomy
- JANET: the UK national academic network
- JIPS: the JANET IP service, which started as a pilot service early in 1991; IP traffic rapidly overtook JANET's native X.25 traffic, and JIPS became an official service in November 1991, about when this message was written
- PSH: a member of IoA staff
- RA:
the Rutherford Appleton Laboratory, a national research institute in Oxfordshirethe Mullard Radio Astronomy Observatory, an outpost at Lords Bridge near Barton, where some of the dishes sit on the old Cambridge-Oxford railway line. (I originally misunderstood the reference.) - RGO: The Royal Greenwich Observatory, which moved from Herstmonceux to the IoA site in Cambridge in 1990
- Starlink: a UK national DECnet network linking astronomical research institutions
Edited to correct the expansion of RA and to add Starlink
Connection of IoA/RGO to IP world
---------------------------------
This note is a statement of where I believe we have got to and an initial
review of the options now open.
What we have achieved so far
----------------------------
All the Suns are properly connected at the lower levels to the
Cambridge IP network, to the national IP network (JIPS) and to the
international IP network (the Internet). This includes all the basic
infrastructure such as routing and name service, and allows the Suns
to use all the usual native Unix communications facilities (telnet,
ftp, rlogin etc) except mail, which is discussed below. Possibly the
most valuable end-user function thus delivered is the ability to fetch
files directly from the USA.
This also provides the basic infrastructure for other machines such as
the VMS hosts when they need it.
VMS nodes
---------
Nothing has yet been done about the VMS nodes. CAMV0 needs its address
changing, and both IOA0 and CAMV0 need routing set for extra-site
communication. The immediate intention is to route through cast0. This
will be transparent to all parties and impose negligible load on
cast0, but requires the "doit" bit to be set in cast0's kernel. We
understand that PSH is going to do all this [check], but we remain
available to assist as required.
Further action on the VMS front is stalled pending the arrival of the
new release (6.6) of the CMU TCP/IP package. This is so imminent that
it seems foolish not to await it, and we believe IoA/RGO agree [check].
Access from Suns to Coloured Book world
---------------------------------------
There are basically two options for connecting the Suns to the JANET
Coloured Book world. We can either set up one or more of the Suns as
full-blown independent JANET hosts or we can set them up to use CS
gateway facilities. The former provides the full range of facilities
expected of any JANET host, but is cumbersome, takes significant local
resources, is complicated and long-winded to arrange, incurs a small
licence fee, is platform-specific, and adds significant complexity to
the system managers' maintenance and planning load. The latter in
contrast is light-weight, free, easy to install, and can be provided
for any reasonable Unix host, but limits functionality to outbound pad
and file transfer either way initiated from the local (IoA/RGO) end.
The two options are not exclusive.
We suspect that the latter option ("spad/cpf") will provide adequate
functionality and is preferable, but would welcome IoA/RGO opinion.
Direct login to the Suns from a (possibly) remote JANET/CUDN terminal
would currently require the full Coloured Book package, but the CS
will shortly be providing X.29-telnet gateway facilities as part of
the general infrastructure, and can in any case provide this
functionality indirectly through login accounts on Central Unix
facilities. For that matter, AST-STAR or WEST.AST could be used in
this fashion.
Mail
----
Mail is a complicated and difficult subject, and I believe that a
small group of experts from IoA/RGO and the CS should meet to discuss
the requirements and options. The rest of this section is merely a
fleeting summary of some of the issues.
Firstly, a political point must be clarified. At the time of writing
it is absolutely forbidden to emit smtp (ie Unix/Internet style) mail
into JIPS. This prohibition is national, and none of Cambridge's
doing. We expect that the embargo will shortly be lifted somewhat, but
there are certain to remain very strict rules about how smtp is to be
used. Within Cambridge we are making best guesses as to the likely
future rules and adopting those as current working practice. It must
be understood however that the situation is highly volatile and that
today's decisions may turn out to be wrong.
The current rulings are (inter alia)
Mail to/from outside Cambridge may only be grey (Ie. JANET
style).
Mail within Cambridge may be grey or smtp BUT the reply
address MUST be valid in BOTH the Internet AND Janet (modulo
reversal). Thus a workstation emitting smtp mail must ensure
that the reply address contained is that of a current JANET
mail host. Except that -
Consenting machines in a closed workgroup in Cambridge are
permitted to use smtp between themselves, though there is no
support from the CS and the practice is discouraged. They
must remember not to contravene the previous two rulings, on
pain of disconnection.
The good news is that a central mail hub/distributer will become
available as a network service for the whole University within a few
months, and will provide sufficient gateway function that ordinary
smtp Unix workstations, with some careful configuration, can have full
mail connectivity. In essence the workstation and the distributer will
form one of those "closed workgroups", the workstation will send all
its outbound mail to the distributer and receive all its inbound mail
from the distributer, and the distributer will handle the forwarding
to and from the rest of Cambridge, UK and the world.
There is no prospect of DECnet mail being supported generally either
nationally or within Cambridge, but I imagine Starlink/IoA/RGO will
continue to use it for the time being, and whatever gateway function
there is now will need preserving. This will have to be largely
IoA/RGO's own responsibility, but the planning exercise may have to
take account of any further constraints thus imposed. Input from
IoA/RGO as to the requirements is needed.
In the longer term there will probably be a general UK and worldwide
shift to X.400 mail, but that horizon is probably too hazy to rate more
than a nod at present. The central mail switch should in any case hide
the initial impact from most users.
The times are therefore a'changing rather rapidly, and some pragmatism
is needed in deciding what to do. If mail to/from the IP machines is
not an urgent requirement, and since they will be able to log in to
the VMS nodes it may not be, then the best thing may well be to await
the mail distributer service. If more direct mail is needed more
urgently then we probably need to set up a private mail distributer
service within IoA/RGO. This would entail setting up (probably) a Sun
as a full JANET host and using it as the one and only (mail) route in
or out of IoA/RGO. Something rather similar has been done in Molecular
Biology and is thus known to work, but setting it up is no mean task.
A further fall-back option might be to arrange to use Central Unix
facilities as a mail gateway in similar vein. The less effort spent on
interim facilities the better, however.
Broken mail
-----------
We discovered late in the day that smtp mail was in fact being used
between IoA and RA, and the name changing broke this. We regret having
thus trodden on existing facilities, and are willing to help try to
recover any required functionality, but we believe that IoA/RGO/RA in
fact have this in hand. We consider the activity to fall under the
third rule above. If help is needed, please let us know.
We should also report sideline problem we encountered and which will
probably be a continuing cause of grief. CAVAD, and indeed any similar
VMS system, emits mail with reply addresses of the form
"CAVAD::user"@.... This is quite legal, but the quotes are
syntactically significant, and must be returned in any reply.
Unfortunately the great majority of Unix systems strip such quotes
during emission of mail, so the reply address fails. Such stripping
can occur at several levels, notably the sendmail (ie system)
processing and the one of the most popular user-level mailers. The CS
is fixing its own systems, but the problem is replicated in something
like half a million independent Internet hosts, and little can be done
about it.
Other requirements
------------------
There may well be other requirements that have not been noticed or,
perish the thought, we have inadvertently broken. Please let us know
of these.
Bandwidth improvements
----------------------
At present all IP communications between IoA/RGO and the rest of the
world go down a rather slow (64Kb/sec) link. This should improve
substantially when it is replaced with a GBN link, and to most of
Cambridge the bandwidth will probably become 1-2Mb/sec. For comparison,
the basic ethernet bandwidth is 10Mb/sec. The timescale is unclear, but
sometime in 1992 is expected. The bandwidth of the national backbone
facilities is of the order of 1Mb/sec, but of course this is shared with
many institutions in a manner hard to predict or assess.
For Computing Service,
Tony Stoneley, ajms@cam.cus
29/11/91